
Help & support
AI is developing rapidly. Appropriate use of AI Systems will help us to achieve our purpose of building a brighter future for all. We recognise that a failure to govern and manage AI Systems effectively may lead to adverse outcomes for our customers and communities, adverse impacts on reputation and customer satisfaction, and potentially result in legal and regulatory action. Our existing risk management framework and policy suites are central to managing these risks.
In recognition of the fast evolving nature of AI, we have developed six principles that are intended to help guide the application, and the further development of, our risk management framework and policy suites, as they apply to the design, development and deployment of AI Systems by the Bank:
The Bank’s use of electricity and water for computing in our Australian data centres is subject to our operational emissions targets.
While we purchase the equivalent of 100% renewable energy for our Australian operations, which includes our Australian data centres within our operational control, much of our AI compute capacity is provided by third-party providers.
We are continuing to work with key suppliers to better understand the climate-related impacts of services they provide to us to gain a more precise and comprehensive picture of our carbon footprint, including with our providers of AI services.
Further information on our progress on targets and our approach to managing our operational and supply chain climate impacts is outlined in our climate reporting.
For further information, see our position on use of AI and renewable energy and water.
We view AI as computer systems capable of performing tasks that typically require human intelligence, such as reasoning, learning, perception, and language understanding.
An AI System is a machine-based system(s) that, for explicit or implicit objectives, infers, from the input it receives, how to generate outputs such as predictions, content, recommendations, or decisions that can influence physical or virtual environments. Different AI Systems vary in their levels of autonomy and adaptiveness after deployment.
The following principles are intended to help guide the application, and the further development of, our existing risk management framework and policy suites, as they apply to the design, development and deployment of AI Systems by the Bank:
Impacts on environmental and social (including human rights) issues, should be considered in the Group’s approach to AI.
AI System outputs should not unfairly discriminate.
What an AI System does should be understandable.
AI Systems should comply with privacy and data protection laws.
AI Systems should perform consistently with their specifications and in accordance with their intended purpose. AI Systems should consider security measures that are proportionate to the potential risks.
Human oversight of AI Systems is necessary. The Group Employee(s) accountable for an AI System should be identified, and accountabilities for an AI System during its lifecycle should be documented.
Brighter AI is a bite-sized video series designed to help everyday Australians build confidence with AI, at work and in life.
Whether you’re a student, educator, job seeker, or simply curious about the possibilities of AI, these short lessons will guide you through practical insights, real-world challenges, and easy-to-follow lessons to empower you to not only understand what AI is, but also know how to harness it in ethical, impactful, and creative ways.
Ready to turn curiosity into capability? Let’s get started.
Discover the basics of Artificial Intelligence and how it’s already part of your everyday life. This module breaks down key types of AI, Machine Learning, Deep Learning, and Generative AI, using relatable examples that you might use every day. Learn why AI matters, how it’s shaping the future of work, and how you can start exploring it today.
Get hands-on with beginner-friendly AI tools and learn how to interact with them using effective prompts. This module shows you how to explore AI safely, with practical tips for protecting your privacy and spotting trustworthy platforms. Build your digital fluency and confidence, one question at a time.
Explore how to build trust in AI by understanding bias, fairness, and ethical use. This module covers why human oversight matters, how to protect your privacy, and how to evaluate AI responses with a critical eye. Learn practical tips to use AI responsibly, at work, in life, and in your community.
Discover how human skills like empathy, adaptability, and critical thinking make you an essential partner to AI. This module explores how people and AI can collaborate across industries—from healthcare to retail—and why emotional intelligence and human judgement are more valuable than ever in an AI-powered world.
Please take a moment to complete this quick, anonymous 2-question survey to help us understand your learning experience and what else you’d like to explore on this topic. Your input helps shape future learning - click below to share your thoughts!
Date: December 10-15, 2024
Location: Vancouver, Canada
CommBank had the opportunity to participate at NeurIPS 2024 as a Bronze Sponsor, supporting one of the most prestigious academic artificial intelligence (AI) conferences globally.
Commbank research presented at NeurIPS 2024:
Date: April 24-28, 2025
Location: Singapore
CommBank had the opportunity to participate at ICLR 2025 as a Gold Sponsor, ICLR is renowned for presenting and discussing novel research in AI and machine learning.
Date: June 11-15, 2025
Location: Nashville, USA
CommBank had the opportunity to participate at CVPR 2025 as a Silver Sponsor, supporting prestigious academic artificial intelligence (AI) conferences globally.
Date: June 10-13, 2025
Location: Sydney, Australia
CommBank was the Award sponsor at PAKDD 2025, one of the leading international conferences for data science, data mining, and knowledge discovery.
Date: June 16-19, 2025
Location: New York, USA
CommBank was awarded Best Full Paper Award at UMAP 2025.
Date: December 2-4, 2024
Location: Canberra, Australia
CommBank had the opportunity to participate & sponsor ALTA 2024 as a Bronze Sponsor. The Australasian Language Technology Association promotes language technology research and development in Australia and New Zealand.
Date: November 30-December 7, 2025
Location: San Diego, USA
CommBank participated at NeurIPS 2025 as a Gold Sponsor, supporting the San Diego edition of the 2025 edition of this prestigious AI/ML academic conference.
Commbank work presented at NeurIPS 2025:
Bridging Research & Reality - Applied AI, Lessons from CommBank on Applied AI
Date: January 20-27, 2026
Location: Singapore
The purpose of the Association for the Advancement of Artificial Intelligence (AAAI) conference is to promote research in AI and foster scientific exchange between researchers, practitioners, scientists, students, and engineers across the entirety of AI and its affiliated disciplines. AI Labs will host the Agentic AI in Financial Services Workshop during AAAI 2026, which aims to bring together researchers and practitioners to explore the latest advances in agentic AI for financial services, fostering discussions and new ideas on design, deployment, ethics and real-world impact.
Authors: Andy Hu, Devika Prasad, Luiz Pizzato, Nicholas Foord, Arman Abrahamyan, Anna Leontjeva, Cooper Doyle, Dan Jermyn
Venue: The 13th IEEE International Conference on Big Data (IEEE BigData 2025)
Publication Date: November 2025
Link: https://arxiv.org/pdf/2508.00954
Summary: At CommBank, we work with large-scale, high-dimensional datasets where feature selection is a critical step for building accurate and efficient models. In this paper, we introduce FeatureCuts, an algorithm that automatically determines the optimal feature cutoff after performing filter ranking. This approach improves feature reduction and significantly reduces computation time compared to traditional and state-of-the-art methods, while overcoming the limitations of fixed-cutoff techniques. Its minimal overhead makes FeatureCuts scalable and practical for enterprise-level machine learning tasks.
Authors: Sandeepa Kannangara, Arman Abrahamyan, Daniel Elias, Thomas Kilby, Nadav Dar, Luiz Pizzato, Anna Leontjeva, Dan Jermyn
Venue: The 13th IEEE International Conference on Big Data (IEEE BigData 2025)
Publication Date: October 2025
Link: https://arxiv.org/abs/2508.03767
Summary: This paper presents MERAI (Massive Entity Resolution using AI), an innovative solution for enterprise-level entity resolution challenges. Designed to handle both record deduplication and cross-dataset matching at scale, MERAI outperforms existing tools by combining exceptional accuracy with robust scalability. While comparable solutions struggle with large datasets, MERAI efficiently processes millions of records with minimal runtime increase, maintaining both high precision and recall. Already successfully implemented across multiple bank projects processing up to 33 million records, MERAI represents a significant advancement in data management technology that ensures accurate customer identification while effectively handling the massive data volumes typical in modern banking operations.
Authors: Arshnoor Kaur, Amanda Aird, Harris Borman, Andrea Nicastro, Anna Leontjeva, Luiz Pizzato, Dan Jermyn
Venue: 33rd ACM International Conference on User Modeling, Adaptation, and Personalization (ACM UMAP 2025 NYC)
Publication Date: June 2025
Link: https://dl.acm.org/doi/pdf/10.1145/3699682.3728339
Summary: In this paper, we tested whether LLM synthetic personas can answer financial wellbeing questions similarly to the responses of a financial wellbeing survey of more than 3,500 Australians. We identified salient biases of 765 synthetic personas using four state-of-the-art LLMs built over 35 categories of personal attributes, noticed clear biases related to age, and as more details were included in the personas, their responses increasingly diverged from the survey toward lower financial wellbeing. With these findings, it is possible to understand the areas in which creating synthetic LLM-based customer personas can yield useful feedback for faster product iteration in the financial services industry and potentially other industries.
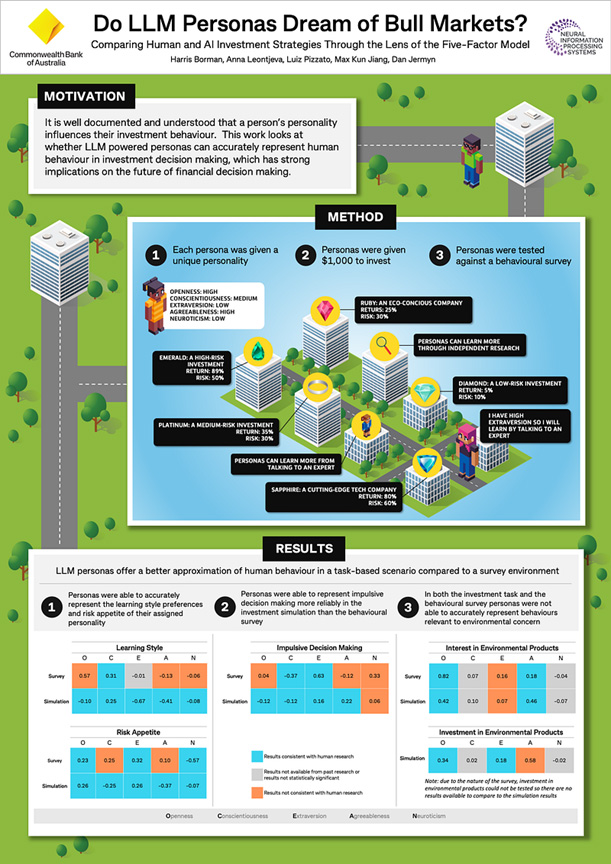
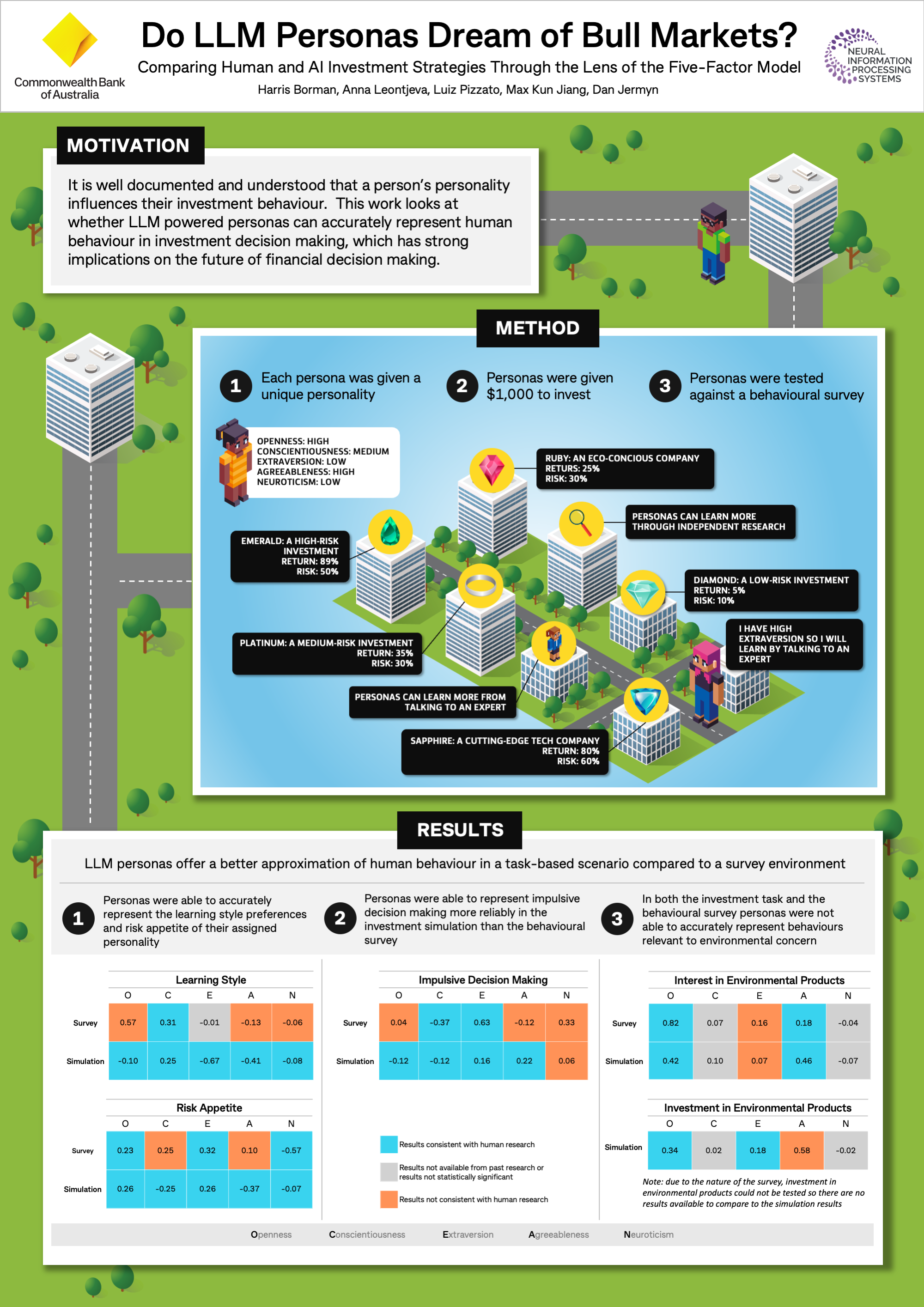
Authors: Harris Borman, Anna Leontjeva, Luiz Pizzato, Max Jiang, Dan Jermyn
Venue: The Thirty-Eighth Annual Conference on Neural Information Processing Systems (Neurips 2024)
Publication Date: December 2024
Link: https://neurips.cc/media/PosterPDFs/NeurIPS%202024/100931.png, https://arxiv.org/pdf/2411.05801
Summary:
In this paper, we explored whether Large Language Models (LLMs) with specific Big Five personality traits behave like humans in investment scenarios. Using a simulated investment task, we found that LLM personas exhibited meaningful and consistent behavioural differences aligned with human expectations in areas such as learning style, impulsivity, and risk appetite. However, environmental attitudes were not accurately replicated. The study also found that LLMs behaved more like humans in simulations than in survey-based environments.
Authors: Dan Jermyn, Luiz Pizzato, Anna Leontjeva, Naomi Ranjbar Kermany, Patrick Songco, Jack Elliott
Venue: IP Australia Patent
Filling date: March 2024
Link: https://ipsearch.ipaustralia.gov.au/patents/2024202048
Authors: Anna Leontjeva, Genevieve Richards, Kaavya Sriskandaraja, Jess Perchman, Luiz Pizzato
Venue: arXiv
Publication Date: March 2023
Link: https://arxiv.org/pdf/2303.08016
Summary: The introduction of longer payment descriptions in Australia's New Payments Platform (NPP) has led to its misuse for communication, including tech-assisted domestic and family abuse. To address this, the Commonwealth Bank of Australia’s AI Labs developed a deep learning-based natural language processing system that detects abusive messages in transaction records. The paper outlines the nature of this abuse, the design and performance of the detection model, and the broader operational framework used to identify and manage high-risk cases.
Authors: Naomi Ranjbar Kermany and Luiz Pizzato in collaboration with Macquarie University
Venue: International Conference on Service-Oriented Computing 2022
Publication Date: November 2022
Link: https://link.springer.com/chapter/10.1007/978-3-031-20984-0_23
Summary: Session-based Recommender Systems (SRSs) typically prioritize recommendation accuracy, often favouring popular items and reducing diversity. However, diversity is important for user engagement and surprise. This study introduces PD-SRS, a Personalized Diversification strategy using graph neural networks to balance accuracy and personalized diversity in recommendations. Comprehensive experiments are carried out on two real-world datasets to demonstrate the effectiveness of PD-SRS in making a trade-off between accuracy and personalized diversity over the baselines.
Authors: Naomi Ranjbar Kermany, Luiz Pizzato, Thireindar Min, Callum Scott, Anna Leontjeva
Venue: RecSys '22: Proceedings of the 16th ACM Conference on Recommender Systems
Publication Date: Sep 2022
Link: https://dl.acm.org/doi/abs/10.1145/3523227.3547388
Summary: Australia’s largest bank, Commonwealth Bank (CBA) has a large data and analytics function that focuses on building a brighter future for all using data and decision science. In this work, we focus on creating better services for CBA customers by developing a next generation recommender system that brings the most relevant merchant reward offers that can help customers save money. Our recommender provides CBA cardholders with cashback offers from merchants, who have different objectives when they create offers. This work describes a multi-stakeholder, multi-objective problem in the context of CommBank Rewards (CBR) and describes how we developed a system that balances the objectives of the bank, its customers, and the many objectives from merchants into a single recommender system.
Authors: Naomi Ranjbar Kermany and Luiz Pizzato in collaboration with Macquarie University
Venue: WSDM '22: Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining
Publication Date: February 2022
Link: https://dl.acm.org/doi/abs/10.1145/3488560.3502191
Summary: In this paper, we demonstrate Fair-SRS, a Fair Session-based Recommendation System that predicts a user's next click by analysing both historical and current sessions. Fair-SRS optimizes recommendations by balancing accuracy and personalized diversity, using Gated Graph Neural Network (GGNN) for session graph embeddings and DeepWalk for node embeddings. This approach captures users' long- and short-term interests, providing fair and diverse recommendations from niche providers. Extensive experiments on real-world datasets show that Fair-SRS outperforms state-of-the-art baselines in delivering accurate and diverse recommendations.
Authors: Naomi Ranjbar Kermany and Luiz Pizzato in collaboration with Macquarie University
Venue: World Wide Web
Publication Date: September 2021
Link: https://link.springer.com/article/10.1007/s11280-021-00946-8
Summary: In this paper, we propose a fairness-aware multi-stakeholder recommender system using a multi-objective evolutionary algorithm (MOEA) to balance provider coverage, long-tail inclusion, personalized diversity, and recommendation accuracy. Our approach introduces a personalized diversification method to align user interests with long-tail recommendations and a P-fairness algorithm to ensure fair provider exposure. Experiments on real-world datasets demonstrate that our method effectively enhances item diversity and provider coverage with minimal accuracy loss.
Author: Luiz Pizzato
Venue: Information Fusion
Publication Date: November 2020
Links: https://www.sciencedirect.com/science/article/abs/pii/S1566253520304267
Summary: In this paper, we introduce and formally characterize Reciprocal Recommender Systems (RRS), which focus on "matching people with the right people" by recommending users to each other. Unlike traditional recommenders, RRS requires mutual acceptance for successful recommendations. We provide a comprehensive literature analysis of RRS research, highlighting algorithms, fusion processes, and key characteristics. We also discuss challenges and opportunities for future research, emphasizing the need for novel fusion strategies, exploration of emerging application domains in social matching, and the potential for extending RRS principles to collective people-to-people recommendations.
Authors: Naomi Ranjbar Kermany and Luiz Pizzato in collaboration with Macquarie University
Venue: IEEE international conference on services computing (SCC)
Publication Date: December 2020
Link: https://ieeexplore.ieee.org/abstract/document/9284606
Summary: In this paper, we introduce an ethical multi-stakeholder recommender system that balances three key objectives: recommendation accuracy, diversity of long-tail items, and provider fairness (P-fairness). By employing a multi-objective evolutionary algorithm (NSGA-II), our system aims to enhance user satisfaction and provider exposure by incorporating lesser-known items into recommendations. Through experiments on real-world datasets, we demonstrate that our method significantly improves item diversity and provider coverage with only a minor loss in accuracy.
Authors: Andrew Clark, Jack Moursounidis, Osmaan Rasouli, William Gan, Cooper Doyle, Anna Leontjeva
Venue: arXiv
Publication Date: October 2025
Link: https://arxiv.org/abs/2510.25074
Summary: Neural networks are expensive to train. We're interested in whether specialized hardware—like neuromorphic devices or quantum feature generators—could efficiently replace or augment network components, but they're "black-box" by nature: no gradients, no auto-differentiation (AD), no dice.
We introduce BOND (Bounded Numerical Differentiation), an adaptive gradient estimation method which achieves AD-equivalent convergence and scales only with the inputs to a black-box. We then show that simulated black-box functions can improve model performance without adding trainable parameters. While computational overhead and functional questions remain, BOND opens the door to hybrid architectures that weren't previously trainable, and hints that the future of efficient ML may not be entirely digital.
Originally published I will never survey a person again by CommBank Distinguished AI Scientist Luiz Pizzato representing his opinions.
Large Language Models (LLMs) have an uncanny ability to impersonate people and their style. Ask ChatGPT to "talk like an Aussie," and you will be treated to gems like, “G'day, mate! How ya goin'?” These charming imitations spark curiosity: could this ability to adopt personas also mimic groups of people's opinions and ideas? And if so, can these synthetic voices become a tool for corporations to get customer views of products during early ideations.

These are precisely the questions the CommBank’s AI Labs team tackled in the paper, which I had the honour to present at the 33rd ACM International Conference on User Modeling, Adaptation and Personalization (UMAP 2025), in New York. In the paper titled “Synthetic Voices: Evaluating the Fidelity of LLM-Generated Personas in Representing People’s Financial Wellbeing,” we explored how LLM personas compare to survey answers by real customers. The paper was honoured with the award for the best full paper at the conference, highlighting its impact and significance in the field. What we found illuminates both opportunities and limitations in using LLM-generated personas for practical applications.
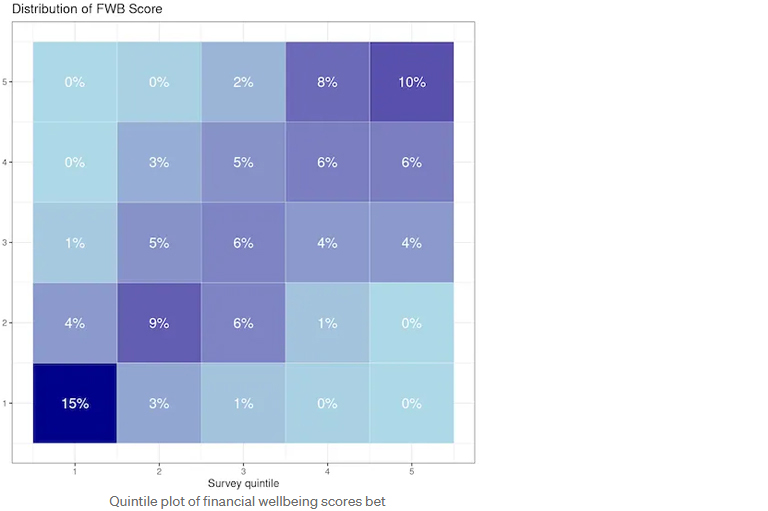
To test the feasibility of using synthetic voices to generate customer insights, we revisited a large scale survey conducted years earlier, where we measured financial wellbeing across four dimensions; whether people can (1) meet their financial obligations; (2) have financial freedom to enjoy life; (3) have control over their finances; (4) have financial security. We then created 765 different types of personas and asked the same survey questions to different LLMs. This resulted in more than 100,000 LLM queries!
1. Can LLM Personas Represent People’s Opinions on Financial Wellbeing?
The results were promising (see image below). The financial wellbeing (FWB) scores generated by LLM personas demonstrated a strong correlation with survey responses, achieving a correlation coefficient of 0.75. This indicates that, on average, LLMs can approximate public opinion trends.
2. Are Certain Groups or Characteristics Better Represented?
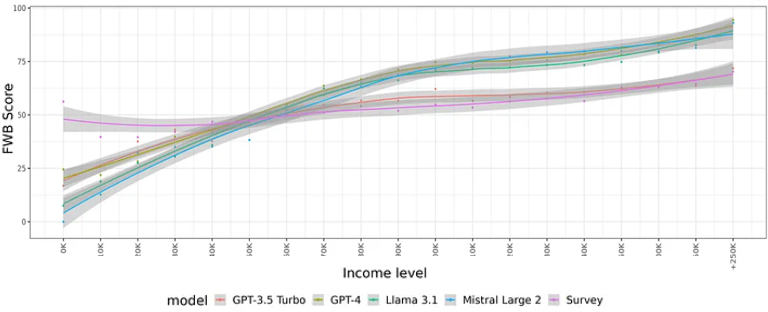
Our study revealed that factors like age, gender, and rural versus metropolitan locations correlated more closely between LLM responses and survey data. However, other characteristics, such as health, gambling habits, and understanding of finances, showed larger deviations. Interestingly but unsurprisingly, LLMs tend to stereotype, exaggerating both positive and negative traits. For instance, income levels were accurately linked to better financial wellbeing, but LLMs often overestimated the impact of higher incomes and underestimated the lower end, creating a steeper-than-reality trend (see image below).
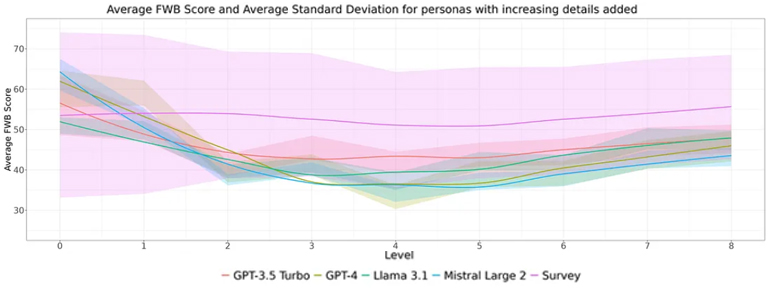
3. How Does Adding More Detail to Personas Affect Responses?
Adding detail to personas yielded mixed results. While more specificity helped LLMs align with real-life trends, it also introduced biases. LLMs often fixated on negative traits when presented with fuller personas, assuming financial struggles.
LLMs are useful but does not replace human feedback
Our findings suggest that LLM-generated personas can be useful for obtaining generalised feedback early in the design process as they do correlate with broader population trends and understanding. However, there are clear limitations as LLMs stereotype populations, lack variability, and fail to capture the nuance of individual human responses. LLM personas are, without a doubt, a valuable tool for obtaining generalised insights and to explore and iterate early conceptual ideas, but it cannot replace the individuality and diversity obtained with human feedback.
Full paper reference
Arshnoor Kaur, Amanda Aird, Harris Borman, Andrea Nicastro, Anna Leontjeva, Luiz Pizzato, and Dan Jermyn. 2025. Synthetic Voices: Evaluating the Fidelity of LLM-Generated Personas in Representing People’s Financial Wellbeing. In Proceedings of the 33rd ACM Conference on User Modeling, Adaptation and Personalization (UMAP '25). Association for Computing Machinery, New York, NY, USA, 185–193.
https://doi.org/10.1145/3699682.3728339
During Hackathon25! 40 teams across CommBank’s Technology Community came together to
explore how Generative AI could solve real challenges for customers and colleagues. A group of
Graduates who, despite only being at the bank for a few months, walked away with the top prize!
Meet GenFolio: a group of engineers and data scientists who met through the Graduate Program
and came together for the Hackathon over a shared ambition to build something impactful.
Their winning solution? An AI-powered dashboard that helps engineers track their work, map it
to the CommBank Engineer Skill Matrix, and receive personalised upskilling recommendation,
all in real time.
The GenFolio team is a mix of engineers and data scientists, each bringing unique backgrounds
and experiences:
Solving real problems
The idea behind GenFolio was born from a common frustration: the challenge of documenting
engineering work and tracking progress against the skills matrix.
“Engineers often get pulled between building and documenting,” explained Tony. “We wanted to
automate that process so they could focus on what they do best.”
The team validated the problem through a survey of fellow Grads and used GenAI to build a
solution that could scale across the engineering and data science functions.
“We realised this wasn’t just our problem, it was shared across the Grad cohort,” said Marella.
“Using GenAI, we made it easier to track tasks and skills proficiency.”
Learning fast, building fast
Despite limited experience with some of the technologies, the team quickly upskilled through
internal workshops hosted by the Hackathon committee. Sessions from AWS, Docker and
GitHub set them up for success.
“The AWS infamous “Working Backwards” session gave us the fundamentals we needed, which
honestly made the biggest difference, “said Marella.
“Getting hands-on with new tools helped us understand what worked and what didn’t,” added
Anna Chan. “We made decisions based on real experimentation.”
Collaboration was key
“The biggest challenge was keeping everyone across the architecture changes,” said Anna. “We
overcame it with ad hoc meetings and lots of whiteboarding.”
“All of us being Grads meant we were on an equal playing field,” said Alex. “Every idea was
considered, and that made our collaboration stronger.”
“We have a team where if you would have removed any single one of us, we wouldn't have
delivered a product at all, or it wouldn't even been nearly the quality that it was - we all played
such a valuable role”, added Alex.
The team’s mentor Kostas observed: “From an outsider point of view, what I witnessed is that
they all played to their own strengths and overcame those challenges that way. You've got data,
you've got engineering, some were strong in software, some had cloud experience. So, they
really played to these strengths and were incredibly well organised.”
Advice for future Hackathon teams
The team had some great advice for anyone thinking about joining the next Hackathon:
“Communicate openly,” said Timothy. “Ask questions, share ideas, and make sure everyone’s on
the same page.”
“Move quickly,” added Jason. “Use AI tools to get your idea to 30% fast, then refine. You can
have all the theory in the world, but you'll learn the most using it practically during something
like a Hackathon.”
“Initially, I was more sceptical about participating than the rest of the team,” admitted Alex. “I
wasn’t even sure we would make the top 40 but thought I could at least benefit from the training
being offered. Then we ended up winning the whole thing! If you told me early on that we were
going to win, I would not have believed you – so really just do it!”
Key Takeaways
“What I enjoyed most was being part of such an exceptional team,” said Marella. “Everyone
brought their strengths, and the discussions were high quality and rewarding.”
“The biggest takeaway was the value of failing fast,” said Timothy. “Start quickly, be flexible, and
progress will come.”
“If you’re thinking about joining the next hackathon - do it,” said James. “You’ll learn, network,
and have fun. Your ideas are valuable, so back yourself.”
What’s Next for GenFolio?
First up: a team dinner to celebrate their win, thanks to a well-earned prize, including a
restaurant voucher. Then?
“Then we’ve got full licence to keep building,” said mentor Eugene. “We’re planning to scale it
out and improve performance management across CommBank.”
Watch this space! GenFolio is just getting started.
CommBank had the opportunity to participate at NeurIPS 2024 as a Bronze Sponsor, supporting one of the most prestigious academic artificial intelligence (AI) conferences globally. It was held in the city of Vancouver bringing together the brightest minds in AI and machine learning (ML) fostering collaboration and innovation on an unparalleled scale.
A Colossal Gathering of Knowledge
NeurIPS 2024 was nothing short of monumental, with nearly 17,000 in-person attendees (20,000 in total) engaging in an extraordinary array of activities. The conference boasted an impressive lineup of 7 keynotes, 14 tutorials, 58 workshops, and much more. The latest research was presented in nearly 4,500 papers both in oral sessions as well as in posters. Suffice to say, it’s an overwhelmingly large conference where you can only attend a small portion of it, and you are left with a lot of homework after the conference. All these dedicated to unravelling the latest advancements and challenges in AI and deep learning research.
Among all of them, these were the highlights:
Listening to a few sessions with luminaries like:
Diving into Specialised Workshops
Given the speed of change in AI and the slow peer review process of such large conferences, the ideas of some of the papers are normally disseminated months ahead of the conference in pre-prints. Hence despite how amazing these top-conferences are, I always feel the biggest value from an attendant perspective comes from workshops, where late breaking ideas and more niche discussing can be had.
One of the standout workshops for me was the Table Representation Learning Workshop (TRL), which delved into novel ways of using deep learning with tabular data within machine learning frameworks. Despite the advancements in transformers and deep learning, XGBoost still reigns supreme in the enterprise because most data in businesses are structured, tabular data. The workshop had some amazing speakers, namely: Matei Zaharia argued that natural language query interfaces for analytics is a better fit for Gen AI than software engineering; Gaël Varoquaux talking about CARTE a table foundation model; and Andreas Mueller talking about MotherNet, a very interesting approach to foundational model for tabular data;
Other workshops worth checking out include:
And last by not least the Workshop on Open-World Agents: Synnergizing Reasoning and Decision-Making in Open-World Environments (OWA-2024) where we presented our paper: Do LLM Personas Dream of Bull Markets? Comparing Human and AI Investment Strategies Through the Lens of the Five-Factor Model
At CommBank, our commitment to advancing artificial intelligence (AI) is a key part our Technology strategy. As a leading financial institution, we recognise the transformative potential of AI in enhancing our services, improving customer experiences, and driving operational efficiency.
Our participation in the International Conference on Learning Representations (ICLR) 2025 in Singapore as a Gold sponsor underscores this commitment. ICLR is well known for presenting and discussing novel research in AI and machine learning, making it an ideal platform for us to engage with the global AI community, share our insights, and learn about the latest advancements in the field.
 Figure 1: CBA Booth was a popular spot
Figure 1: CBA Booth was a popular spot
ICLR 2025 featured a range of research with over 11,000 submissions, approximately 32% acceptance rate, and 3,827 papers accepted. Submissions increased by over 60% from the previous year, reflecting the rapid growth of the AI field.
In terms of the main trends, the conference highlighted topics from agentic AI systems and multi-step reasoning to new fine-tuning strategies, advances in foundational models, and a strong emphasis on AI safety, alignment and real-world deployment.
We're excited to share trends and key takeaways from the conference, including insights from a selection of papers, workshops, and talks.
Agentic Systems and Open-ended Learning
Research of agentic AI systems was more prominent compared to NeurIPS 2024. Key talks emphasised open-ended learning approaches for such agents. For example, in his keynote, Tim Rocktäschel (Google DeepMind and University College London) advocated for training agents via “foundation world models” that generate diverse simulated environments, enabling agents to acquire more general and robust behaviours (see Figure 1). This open-ended paradigm aims to produce AI agents that can endlessly generate and tackle novel tasks, moving beyond narrowly optimised solutions. Early results are promising, we’re seeing self-referential self-improvement loops where AI agents can refine themselves through automated prompt engineering, automated red-teaming, and even AI-vs-AI debates.
The drive toward agentic models matters because next-generation AI will likely need to operate autonomously in complex, changing environments. We should start thinking about how to design and evaluate systems in CommBank that learn from interaction and remain adaptive when facing unforeseen tasks.
Another recommended paper in the field of Agentic would be AFlow: Automating Agentic Workflow Generation by Jiayi Zhang et al. is a framework designed to automate the creation of agentic workflows using Monte Carlo Tree Search (MCTS). It refines workflows through code modifications and execution feedback. Initial experiments show promising results but highlight the need for further research, particularly for complex tasks in banking.
 Figure 2: A demonstration of Genie 2 model that can generate a game from an input image
Figure 2: A demonstration of Genie 2 model that can generate a game from an input image
Fine-Tuning and Adaptation Techniques
With foundation models now widespread, a practical challenge is how to adapt these large models efficiently to specific tasks or evolving data. ICLR 2025 highlighted many advances in fine-tuning methods that make adaptation more accessible. A recurring theme was parameter-efficient fine-tuning: instead of retraining massive models from scratch, researchers are devising lightweight adapters (e.g. LoRA modules) that tweak only small portions of the model.
While this method is not new, ICLR 2025 was rich of various improvements over existing LoRA methods. One standout paper introduced LoRA-X, a technique allowing fine-tuning parameters to be transferred between different base models without any retraining. This approach addresses a common problem – when a foundation model is upgraded or replaced, we can carry over the learned task-specific adaptors without needing the original training data or costly re-training. Such innovations mean practitioners can keep models up-to-date and domain-specialised with minimal compute overhead.
More broadly, the conference underscored that adaptability is crucial for real-world AI: future systems should be easy to fine-tune on new tasks or data.
Some additional papers in the fine-tuning space worth highlighting include:
AlphaEdit: Null-Space Constrained Knowledge Editing for Language Models by Junfeng Fang et al. introduces AlphaEdit, a novel method for updating specific knowledge in Large Language Models (LLMs) without disrupting existing information. By projecting parameter updates onto the null space of preserved knowledge, AlphaEdit ensures that new edits are localised. This approach improves the preservation of original knowledge by 36% in GPT and LLama models.
Preserving Diversity in Supervised Fine-Tuning of Large Language Models by Ziniu et al. presents Entropic Distribution Matching (EDM), a technique to mitigate overfitting and loss of output diversity during supervised fine-tuning. EDM aligns the output distribution of the fine-tuned model with that of the pre-trained model, thereby maintaining the model's ability to generate diverse responses. This method enhances generalisation and robustness across various tasks.
Evolving Foundation Models
This year ICLR demonstrated that foundation models remain central topic in AI research, but the focus is shifting from simply scaling up model size to understanding and extending these models’ capabilities. Many works addressed issues like bounding model capabilities, reducing hallucinations, and using synthetic data to overcome training data gaps.
This reflects a maturation of the field: rather than chasing ever-bigger architectures, researchers are consolidating knowledge about how to optimise and reliably deploy the powerful models we already have.
At the same time, foundation models are expanding in scope. New multimodal models unveiled at ICLR can handle new modalities. For example, one presentation showed a hierarchical vision-language-action model (HAMSTER from NVIDIA), that transfers knowledge from simulations to real-world robotics tasks.
Researchers also showcased architecture innovations (such as hybrid Transformer–state-space models) to make large models more efficient in handling long contexts and high throughput.
Notably, a keynote by Danqi Chen highlighted that academia is finding ways to contribute to foundation model development by innovating under resource constraints – for instance, building smaller but capable models, improving training data quality, and layering new fine-tuning methods on open-source models. All these efforts indicate that foundation models are evolving not just in size, but in versatility and accessibility.
We can expect the next generation of foundation models that are more efficient, cover multiple modalities, and be easier to adapt in smaller settings.
Focus on AI Safety and Robustness
Finally, AI safety was a significant theme at ICLR 2025, indicating an increasing awareness that more advanced models need to be reliable and aligned with human intentions. Several invited talks addressed how to build safe and secure AI systems. Zico Kolter’s talk, for example, was focused on building robust AI systems that enforce strict safety constraints on models. He discussed recent techniques to harden models against adversarial exploits and “jailbreak” attacks, such as robustness at the training stage and even data pre-filtering stage to prevent users from manipulating an LLM’s outputs in harmful ways.
As AI systems become more agentic and ubiquitous, there is a greater need to integrate safety by design – from rigorous testing for adversarial robustness to implementing guardrails that align model behaviour with ethical and policy requirements.
ICLR 2025’s focus on safety underscores that future ML systems will be judged not only on performance, but on trustworthiness and safety robustness.
ICLR 2025 Discussions
Many fascinating discussions were about the potential impact of AI model collapse, attributed to insufficient human training and the use of iterations of LLM-generated text as inputs for subsequent versions of LLM models.
This conversation has paralleled emerging concept of ‘the Era of Experience’ introduced by David Silver and Richard S. Sutton’s paper suggesting that we are transitioning from the era of data to the era of learning from environment similarly to Reinforcement learning concepts of AlphaGo era.
Alongside these developments, the ICLR community has increasingly questioned the adequacy of current evaluation methods, noting that existing benchmarks tend to saturate too quickly and may not effectively reflect real-world challenges, emphasising the need for more sophisticated and realistic eval frameworks.
Conclusion
The research directions highlighted at ICLR 2025 paint a picture of an AI field striving for both greater capability and greater responsibility. Trends like agentic models and adaptive fine-tuning point toward AI that is more autonomous and flexible, able to handle open-ended challenges and continuously learn.
At the same time, the evolution of foundation models, concerns of AI model collapse and the emphasis on safety show a commitment to making these powerful frameworks more usable, reliable, and data selective. Overall, ICLR 2025 was a great opportunity for us to understand what to expect next in this ever-evolving field.
Explore more insights on AI and Technology through our CommBank Technology Blog on Medium.
At CommBank, we recognise the benefits that open-source software brings to the broader community. We support the open-source software ecosystem through our industry partnerships, sponsorships, use of and contribution to open-source software.
CommBank supports the development and adoption of open and interoperable software and participates in open-source communities that promote collaboration, shared standards and industry innovation.
Our sponsorship reflects CommBank’s broader work and commitment to advancing AI research including through our research partnerships and collaboration with academic institutions.





{kind=link}